Contributed by Ankur Goyal on 2024-07-29
Although there are a small handful of open-source LLMs, there are a variety of inference providers that can host them for you, each with different cost,
speed, and as we’ll see below, accuracy trade-offs. And even if one provider excels at a certain model size, it may not be the best choice for another.
Key takeaways
It’s very important to evaluate your specific use case against a variety of both models and providers to make an informed decision about which to use. What I learned is that the results are pretty unpredictable and vary across both provider and model size. Just because one provider has a good 8b model, doesn’t mean that its 405b is fast or accurate. Here are some things that surprised me:- 8b models are consistently fast, but have high variance in accuracy
- One provider is fastest for 8b and 70b, yet slowest for 405b
- The best provider is different across the two benchmarks we ran
Setup
Before you get started, make sure you have a Braintrust account and API keys for all the providers you want to test. Here, we’re testing Together, Fireworks, and Lepton, although Braintrust supports several others (including Azure, Bedrock, Groq, and more). Make sure to plug each provider’s API key into your Braintrust account’s AI secrets configuration and acquire aBRAINTRUST_API_KEY.
Put your BRAINTRUST_API_KEY in a .env.local file next to this notebook, or just hardcode it into the code below.
Task code
We are going to reuse the task function from Tool calls in LLaMa 3.1, which is below. For a detailed explanation of the task, see that recipe.Dataset
We’ll use the same data as well: a subset of the CoQA dataset.Running evals
Let’s create a list of the providers we want to evaluate. Each provider conveniently names its flavor of each model slightly differently, so we can use these as a unique identifier. To facilitate this test, we also self-hosted an official Meta-LLaMa-3.1-405B-Instruct-FP8 model, which is available on Hugging Face using vLLM. You can configure this model as a custom endpoint in Braintrust to use it alongside other providers.Provider map
Eval code
We’ll run each provider in parallel, and within the provider, we’ll run each model in parallel. This roughly assumes that rate limits are per model, not per provider. We’re also running with a low concurrency level (3) to avoid overwhelming a provider and hitting rate limits. The Braintrust proxy handles rate limits for us, but they are reflected in the final task duration. You’ll also notice that we parse and track the provider as well as the model in each experiment’s metadata. This allows us to do some rich analysis on the results.Results
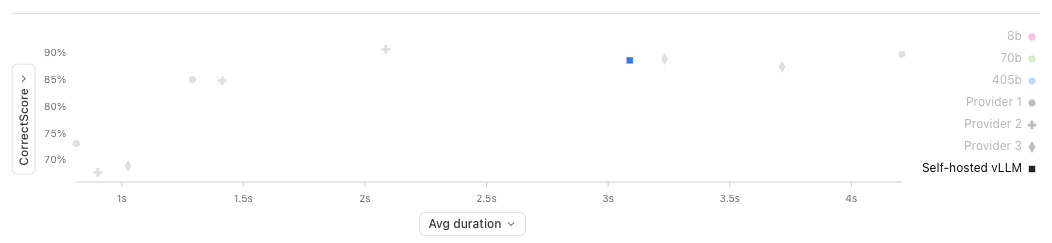
Let’s start by looking at the project view. Braintrust makes it easy to morph this into a multi-level grouped analysis where we can see the score vs. duration in a scatter plot, and how each provider stacks up in the table.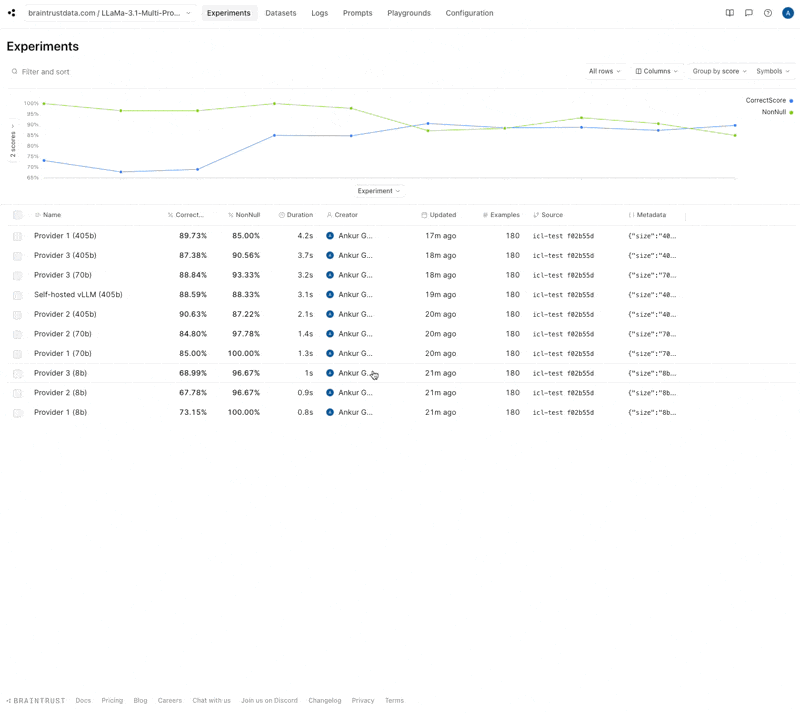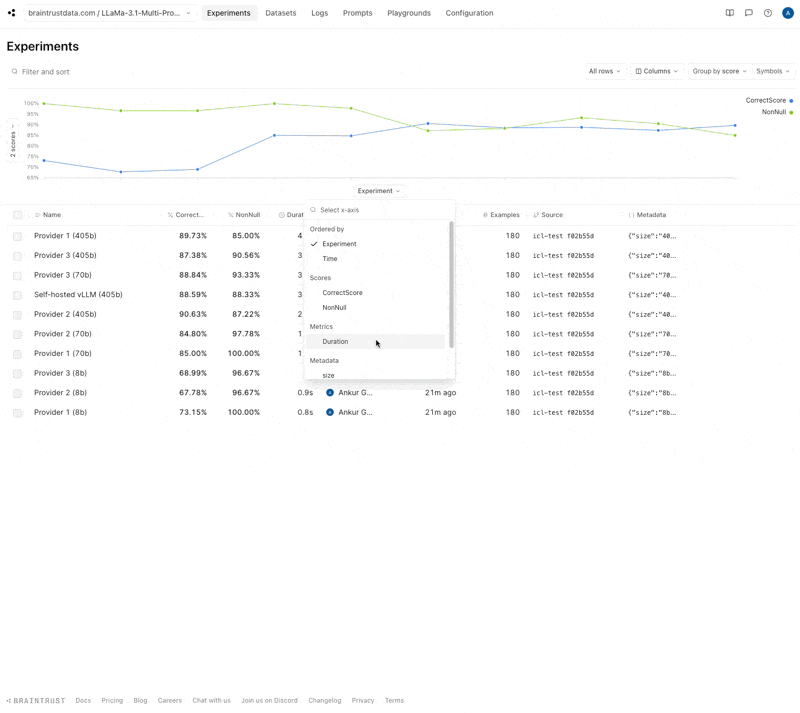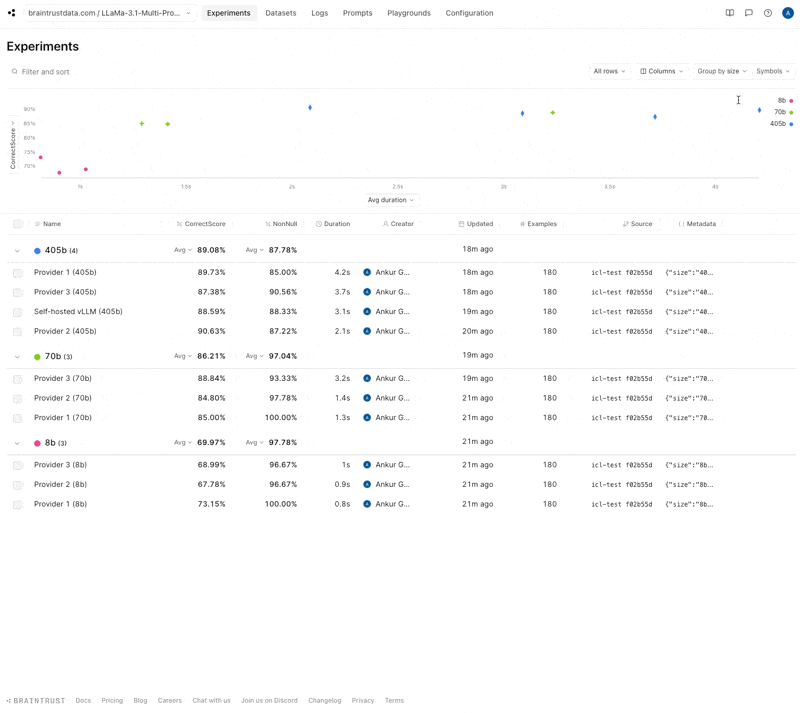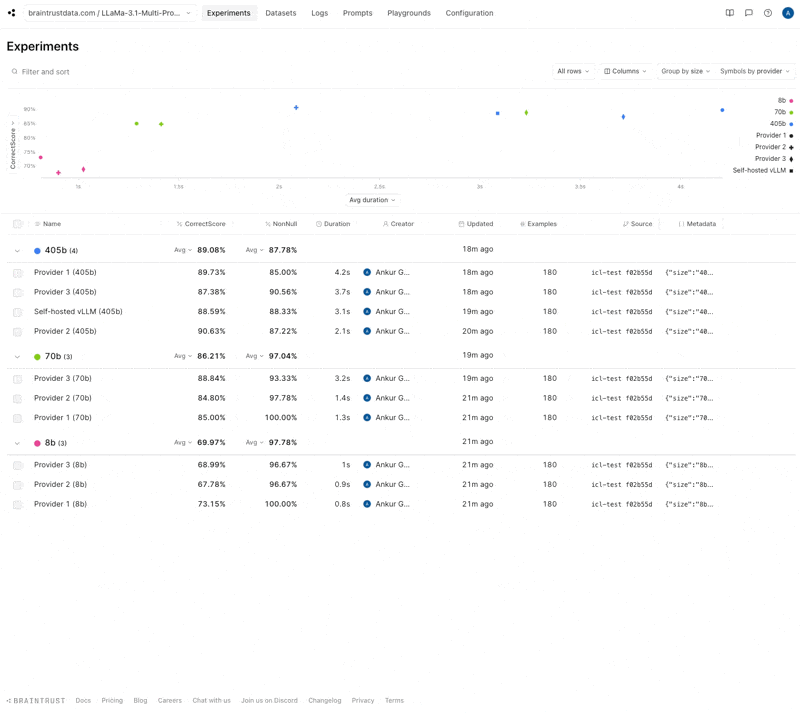
Insights
Now let’s dig into this chart and see what we can learn.- 70b hits a nice sweet spot
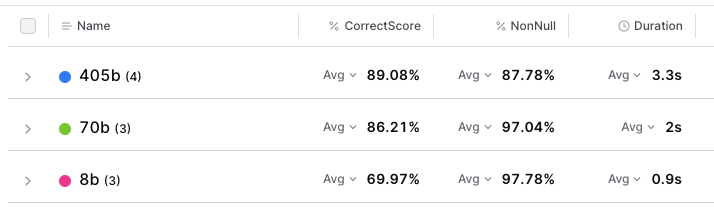
- 8b models are consistently really fast, but some providers’ 70b models are slower than others’
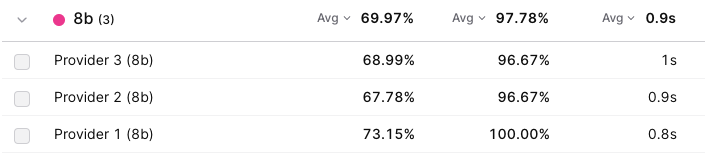
- High accuracy variance in 8b models
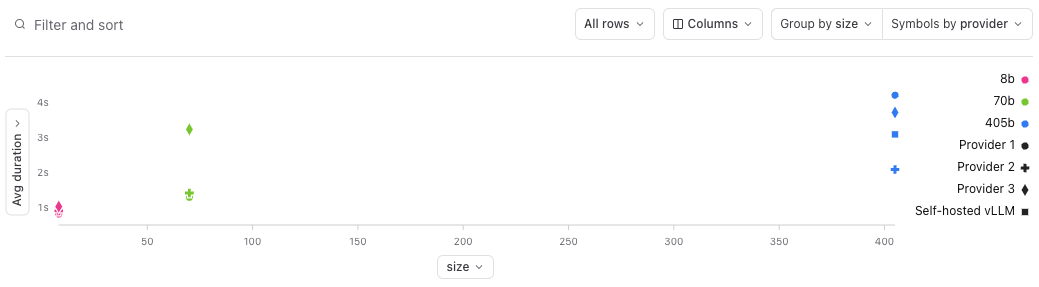
- Provider 1 is the fastest except for 405b
- Self-hosting strikes a nice balance
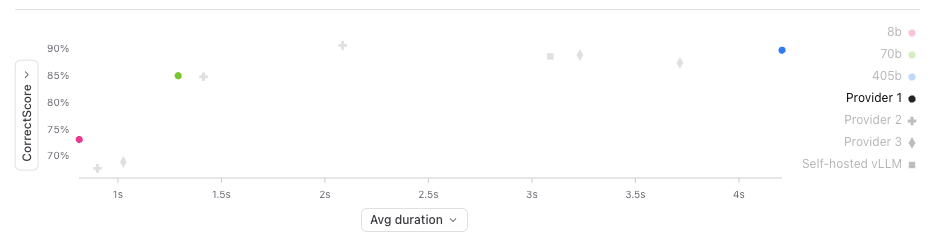
Another benchmark
We also used roughly the same code on a different, more-realistic, internal benchmark which measures how well our AI search bar works. Here is the same visualization for that benchmark: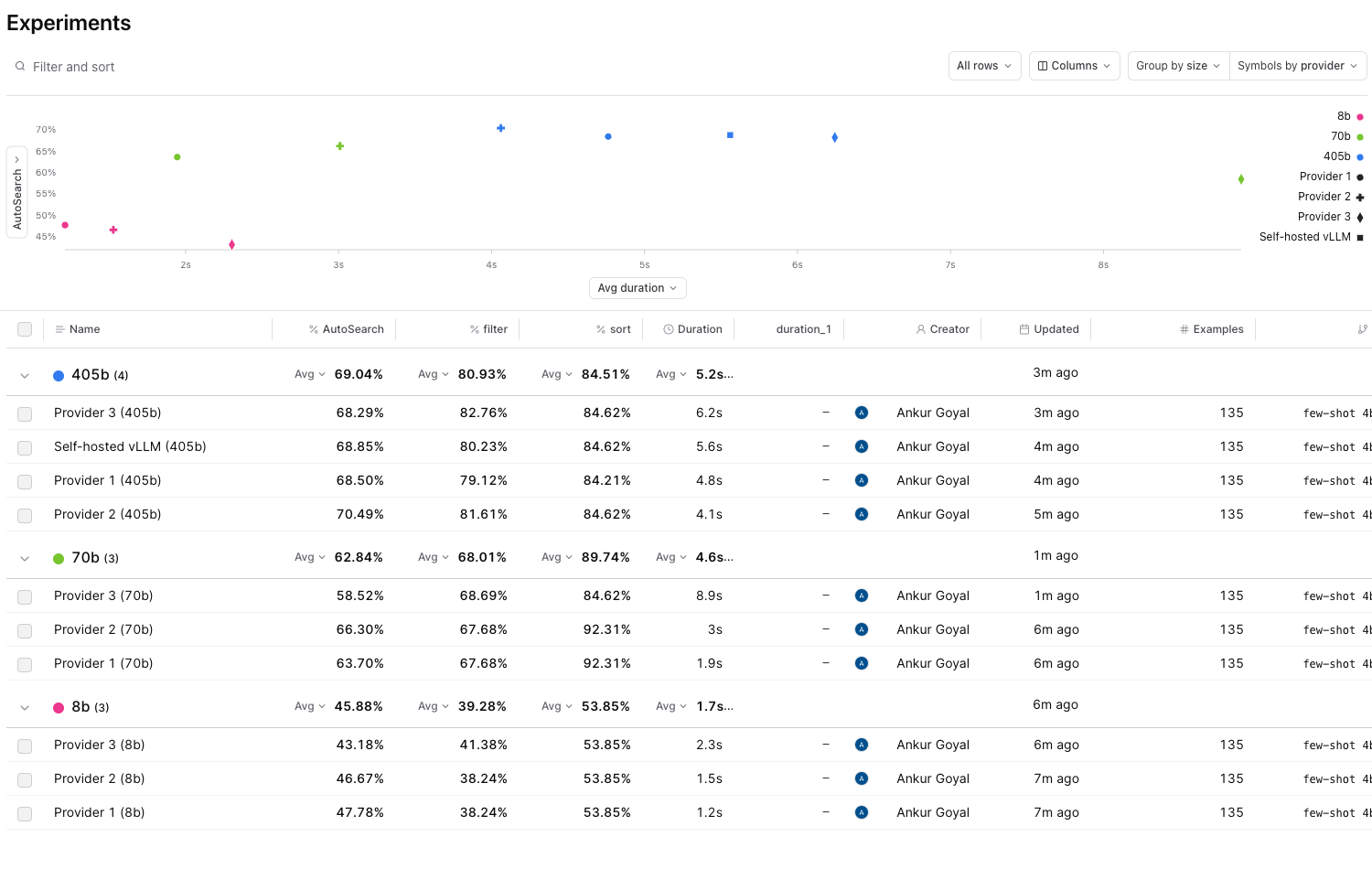
- Provider 1 is less differentiated. Although Provider 1 is still the fastest, it comes at the cost of accuracy in the 70b and 405b classes, where Provider 2 wins on accuracy. Provider 2 also wins on speed for 405b.
- Provider 3 has a hard time in the 70b class. This workload is heavy on prompt tokens (~3500 per test case). Maybe that has something to do with it?
- More latency variance across the board. Again, this may have to do with the significant jump in prompt tokens.
- Self-hosted seems to be about the same. Interestingly, the self-hosted model appears at about the same spot in the graph!