Contributed by Ankur Goyal on 2024-05-29
In this cookbook, we’re going to work through a Text2SQL use case where we are starting from scratch without a nice and clean
dataset of questions, SQL queries, or expected responses. Although eval datasets are popular in academic settings, they are often
not practically available in the real world. In this case, we’ll build up a dataset using some simple handwritten questions and
an LLM to generate samples based on the SQL dataset.
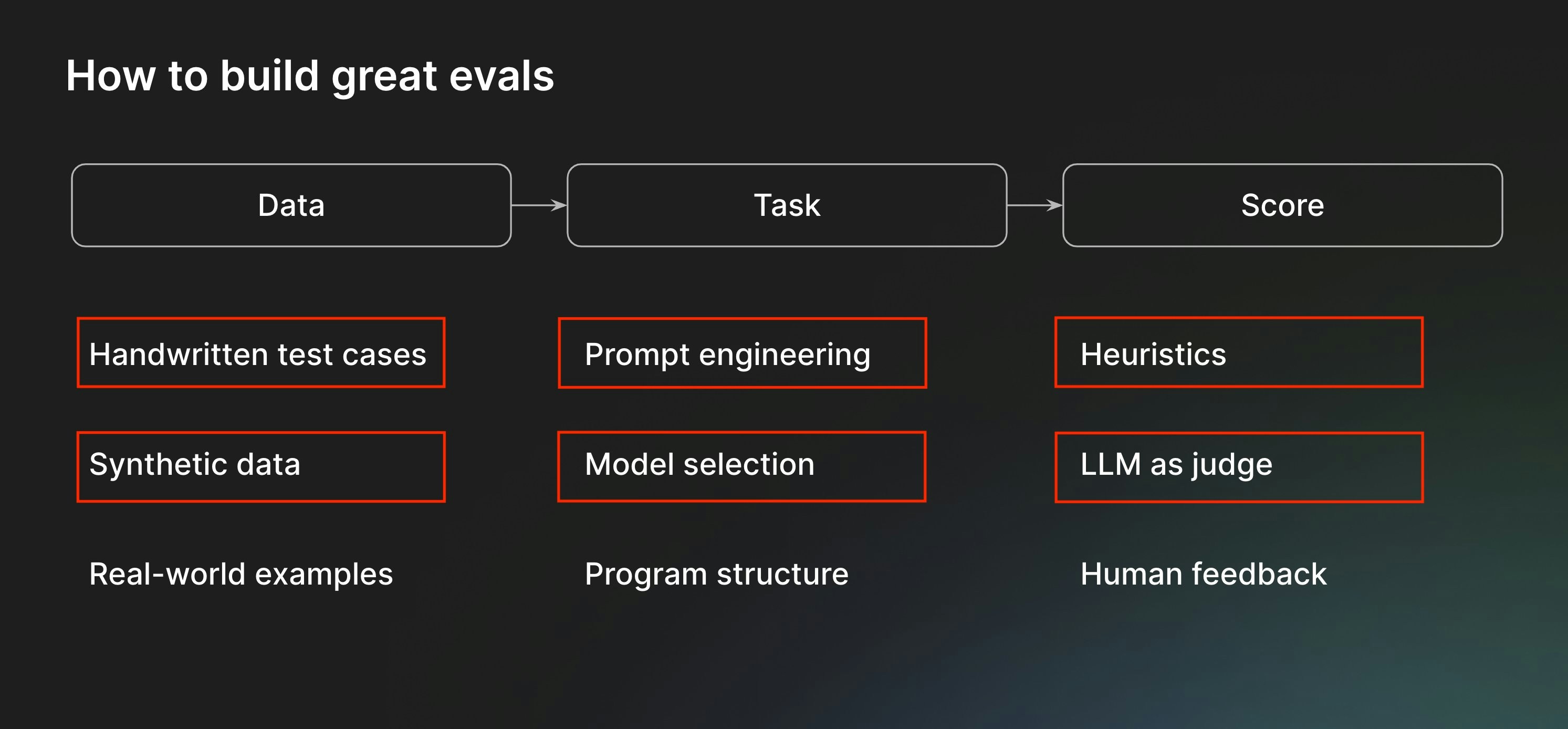
Along the way, we’ll cover the following components of the eval process:
Setting up the environment
The next few commands will install some libraries and include some helper code for the text2sql application. Feel free to copy/paste/tweak/reuse this code in your own tools.Downloading the data
We’re going to use an NBA dataset that includes information about games from 2014-2018. Let’s start by downloading it and poking around. We’ll use DuckDB as the database, since it’s easy to embed directly in the notebook.Prototyping text2sql
Now that we have the basic data in place, let’s implement the text2sql logic. Don’t overcomplicate it at the start. We can always improve its implementation later!Initial evals
AnEval() consists of three parts — data, task, and scores. We’ll start with data.
Creating an initial dataset
Let’s handwrite a few examples to bootstrap the dataset. It’ll be a real pain, and probably brittle, to try and handwrite both questions and SQL queries/outputs. Instead, we’ll just write some questions, and try to evaluate the outputs without an expected output.Task function
Now let’s write a task function. The function should take input (the question) and return output (the SQL query and results).Scores
At this point, there’s not a lot we can score, but we can at least check if the SQL query is valid. If we generate an invalid query, theerror field will be non-empty.
Eval
And that’s it! Now let’s plug these things together and run an eval.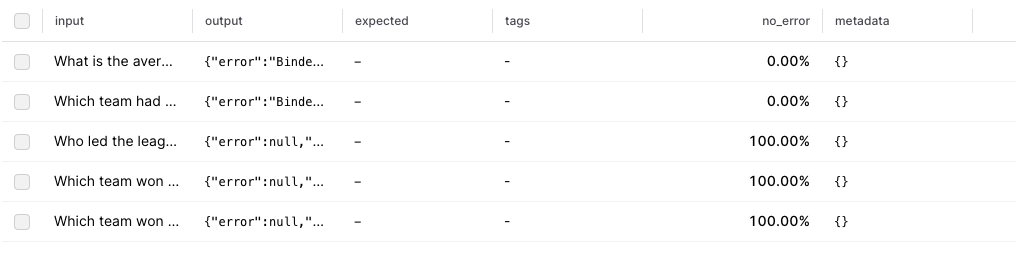
Interpreting results
Now that we ran the initial eval, it looks like two of the results are valid, two produce SQL errors, and one is incorrect. To best utilize these results:- Let’s capture the good data into a dataset. Since our eval pipeline did the hard work of generating a reference query and results, we can now save these, and make sure that future changes we make do not regress the results.
- The incorrect query didn’t seem to get the date format correct. That would probably be improved by showing a sample of the data to the model.

- There are two binder errors, which may also have to do with not understanding the data format.

Updating the eval
Let’s start by reworking ourdata function to pull the golden data we’re storing in Braintrust and extend it with the handwritten questions. Since
there may be some overlap, we automatically exclude any questions that are already in the dataset.
Generating more data
Now that we have a basic flow in place, let’s generate some data. We’re going to use the dataset itself to generate expected queries, and have a model describe the queries. This is a slightly more robust method than having it generate queries, because we’d expect a model to describe a query more accurately than generate one from scratch.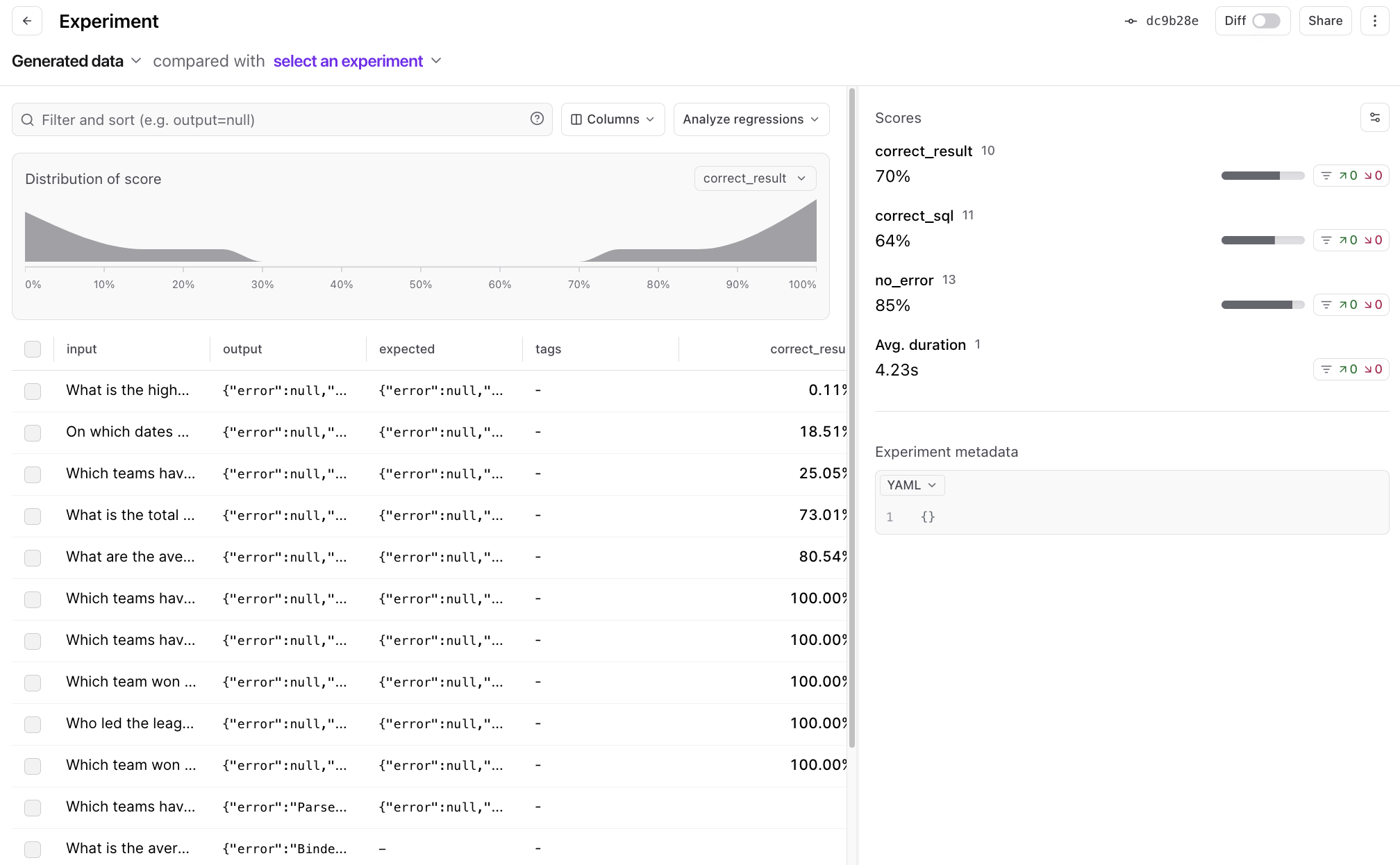
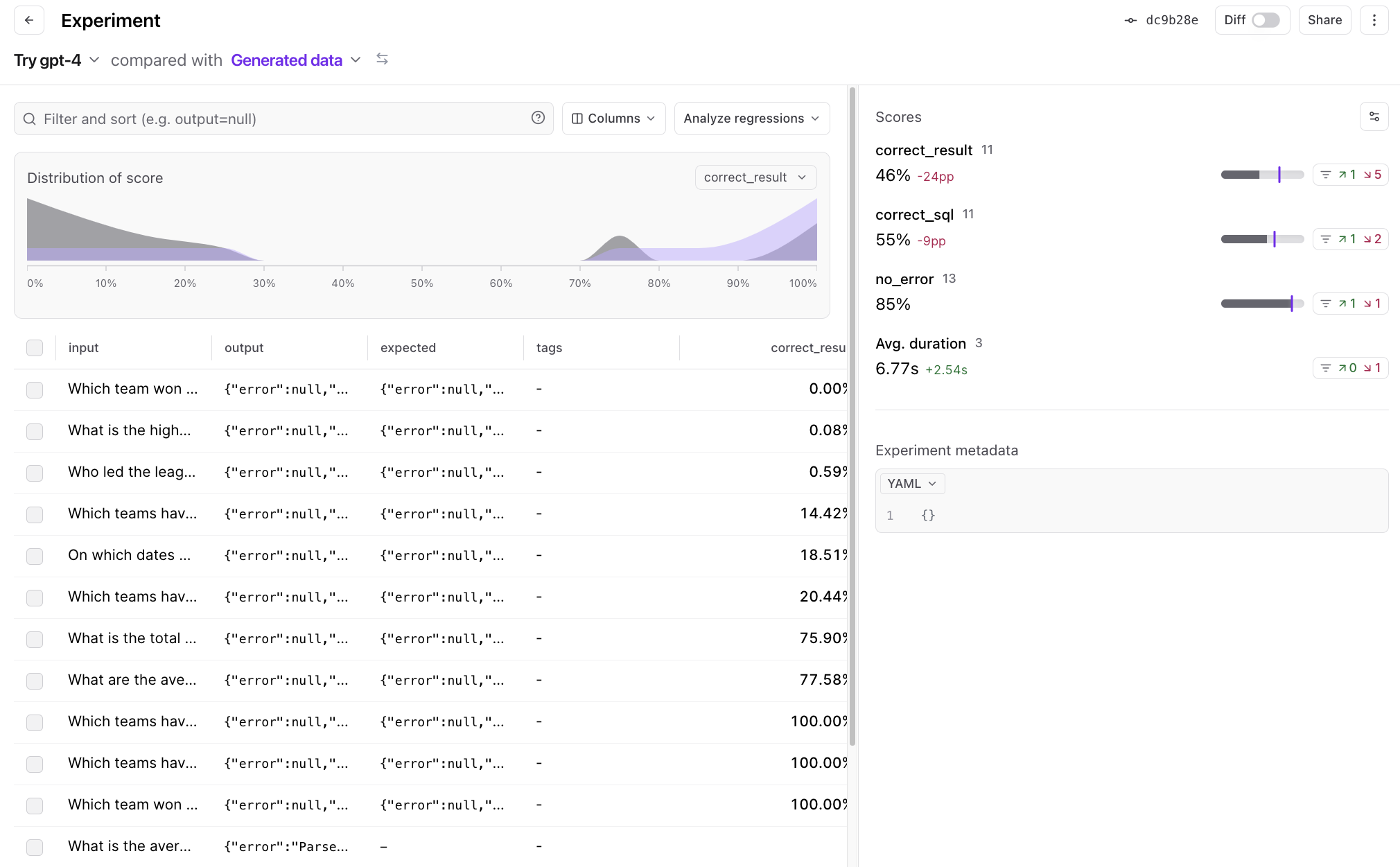
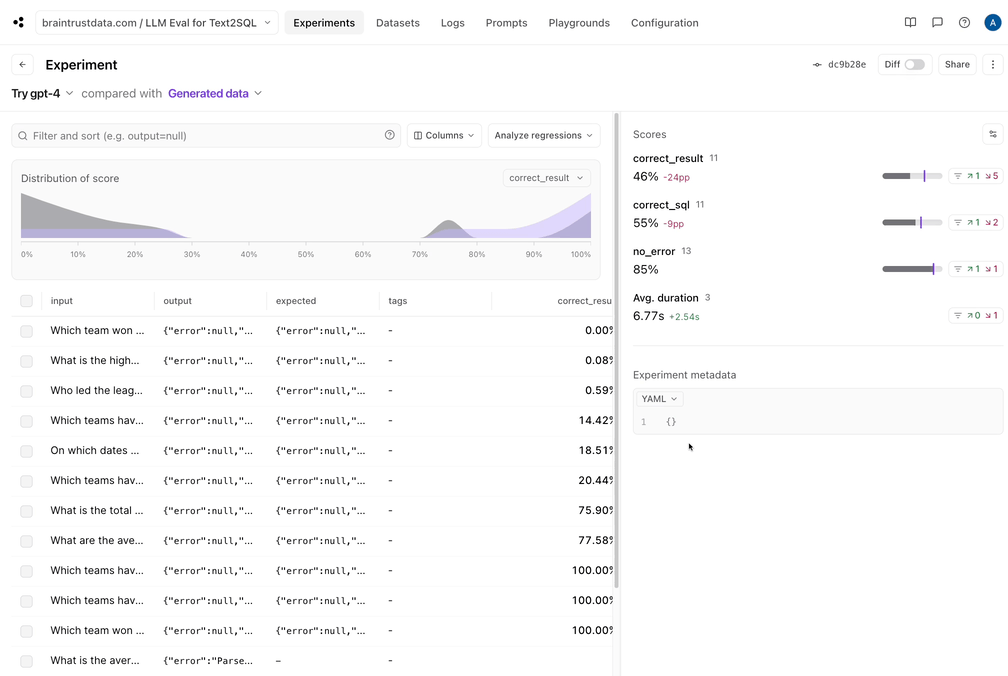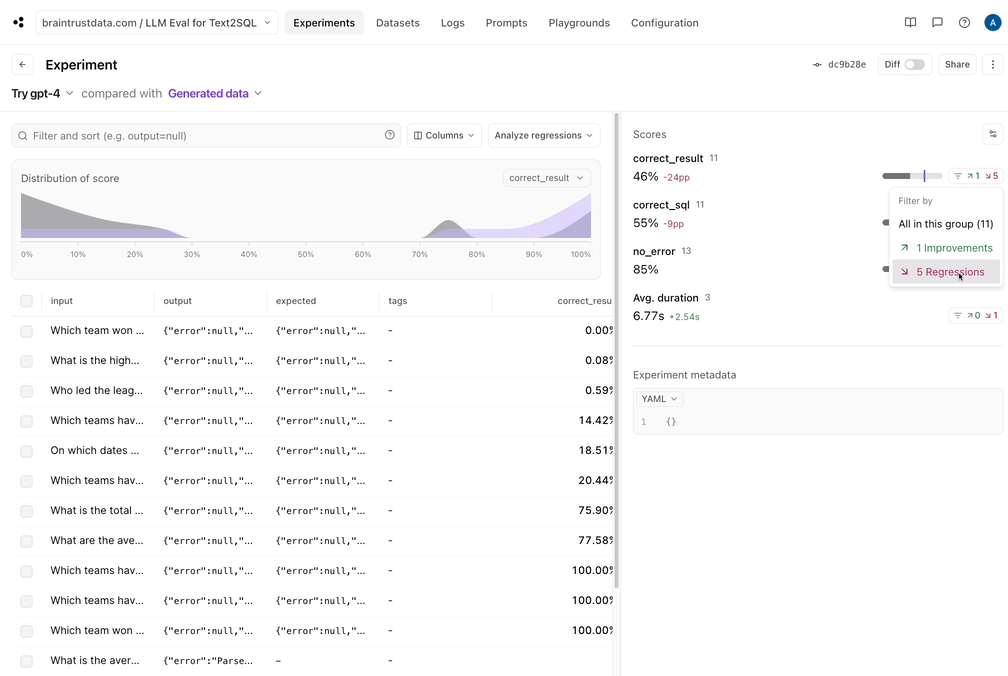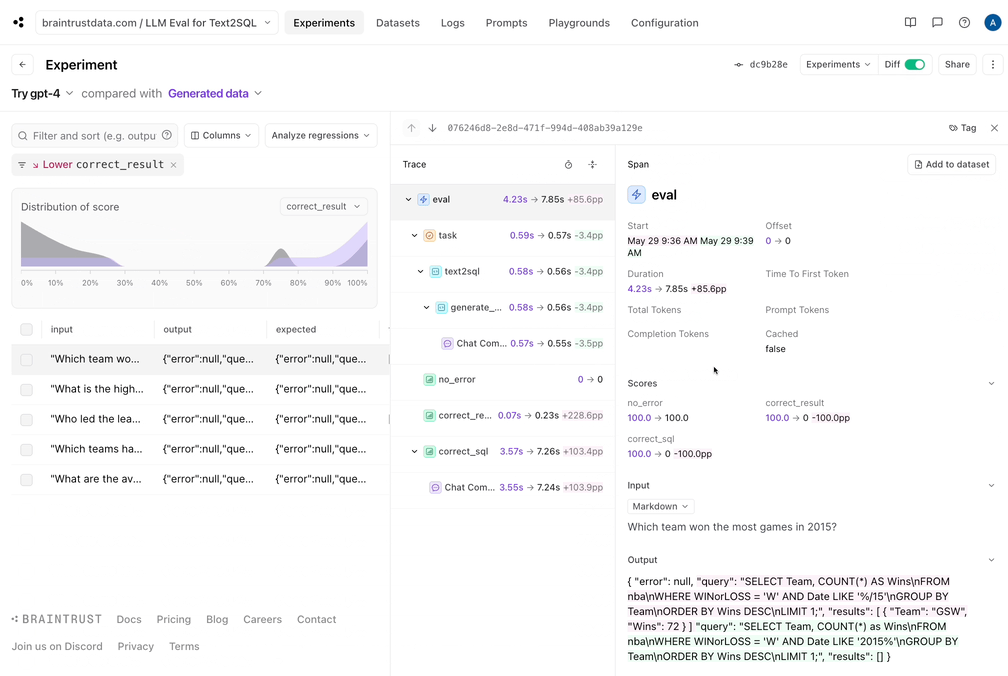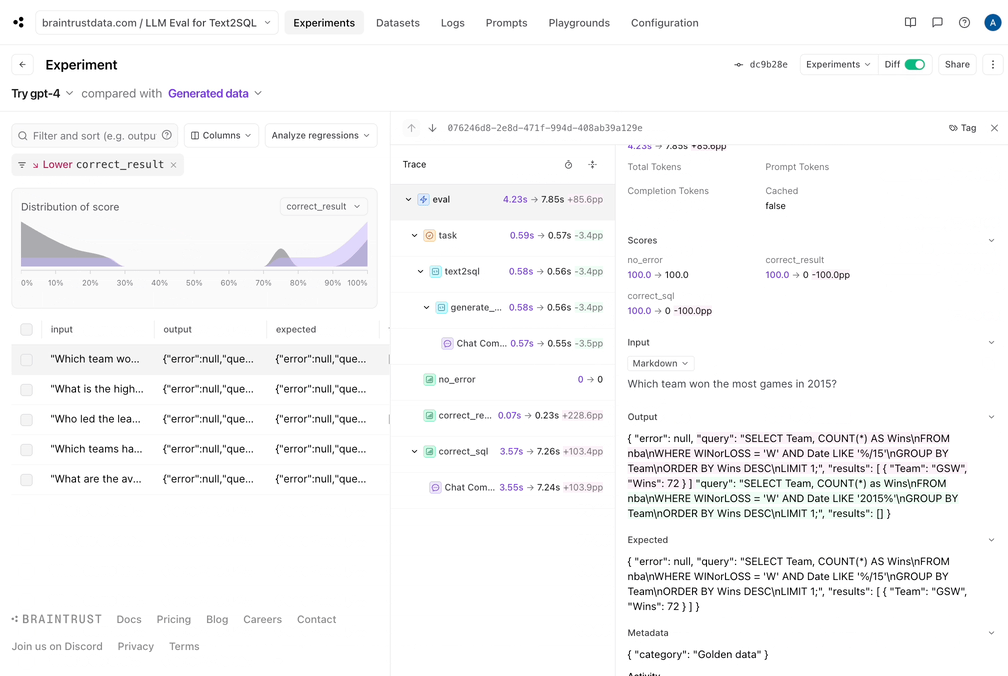
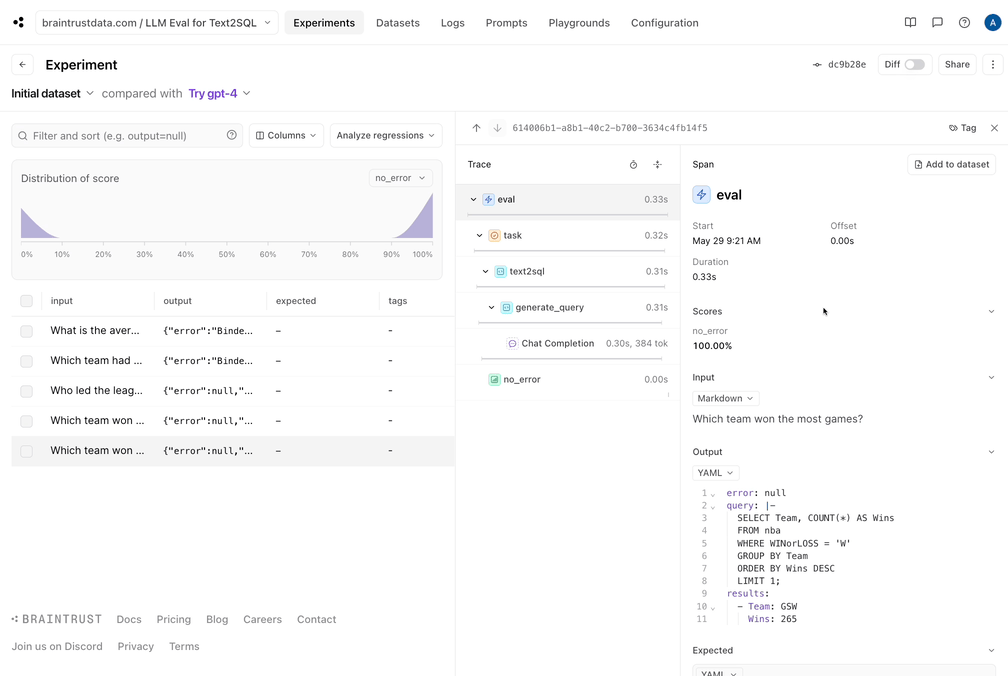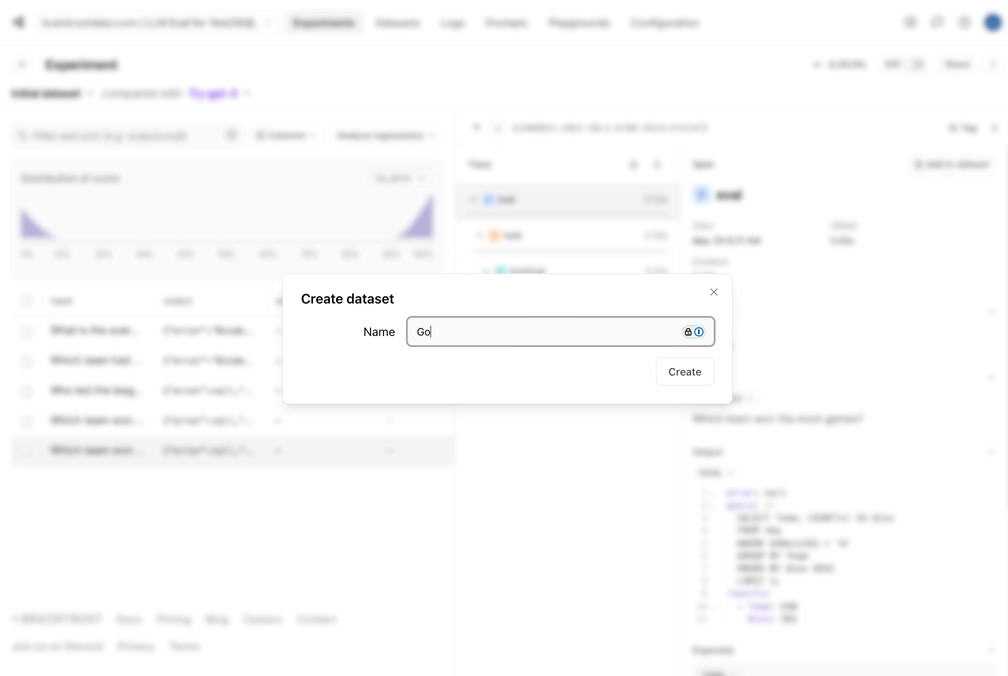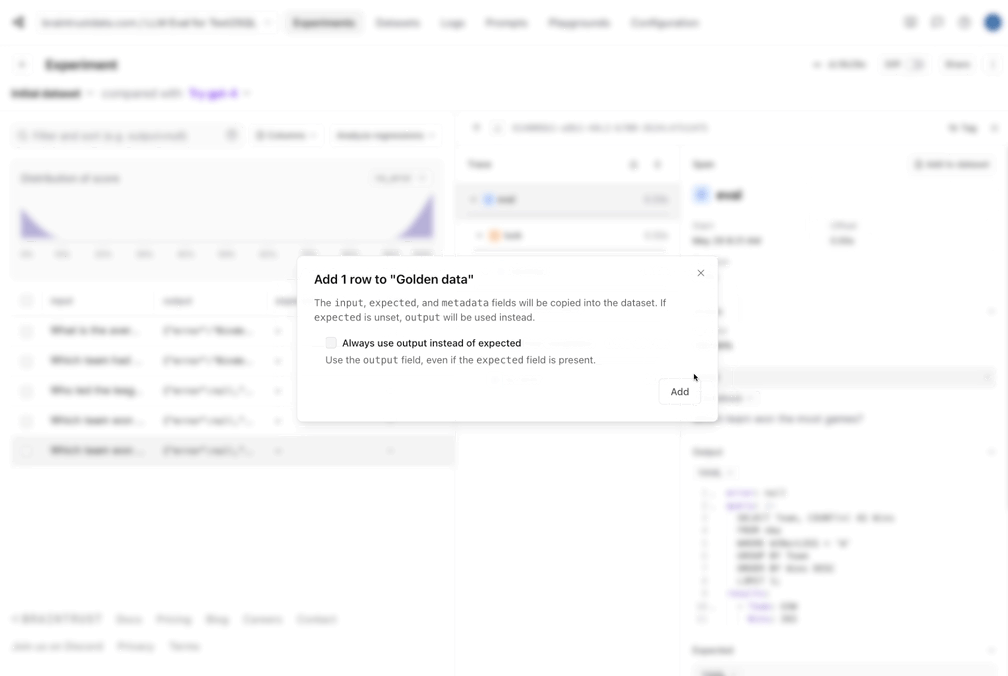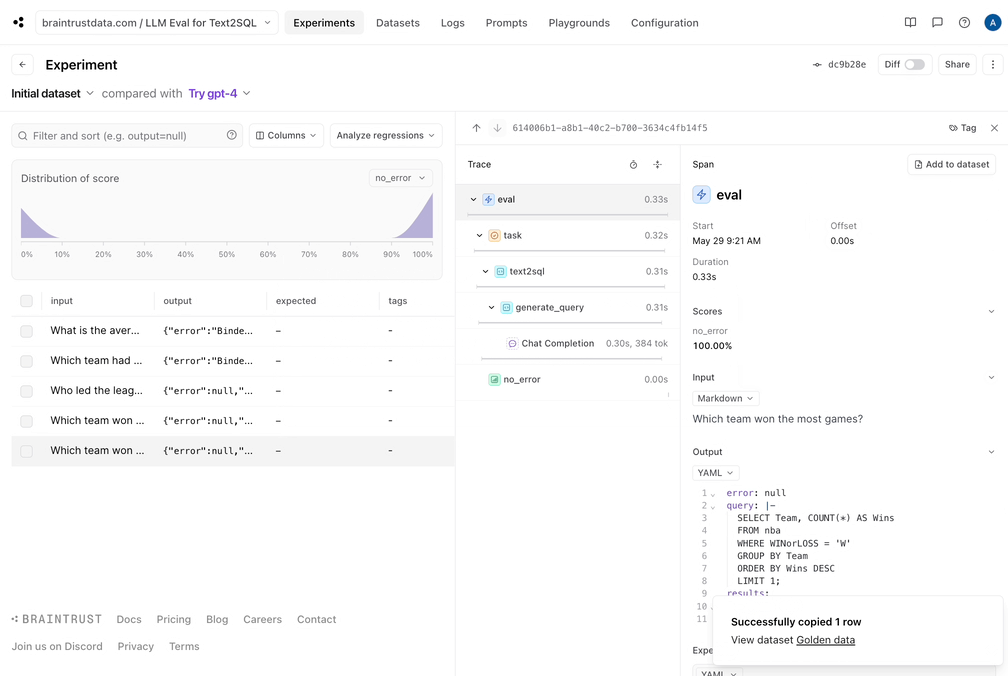
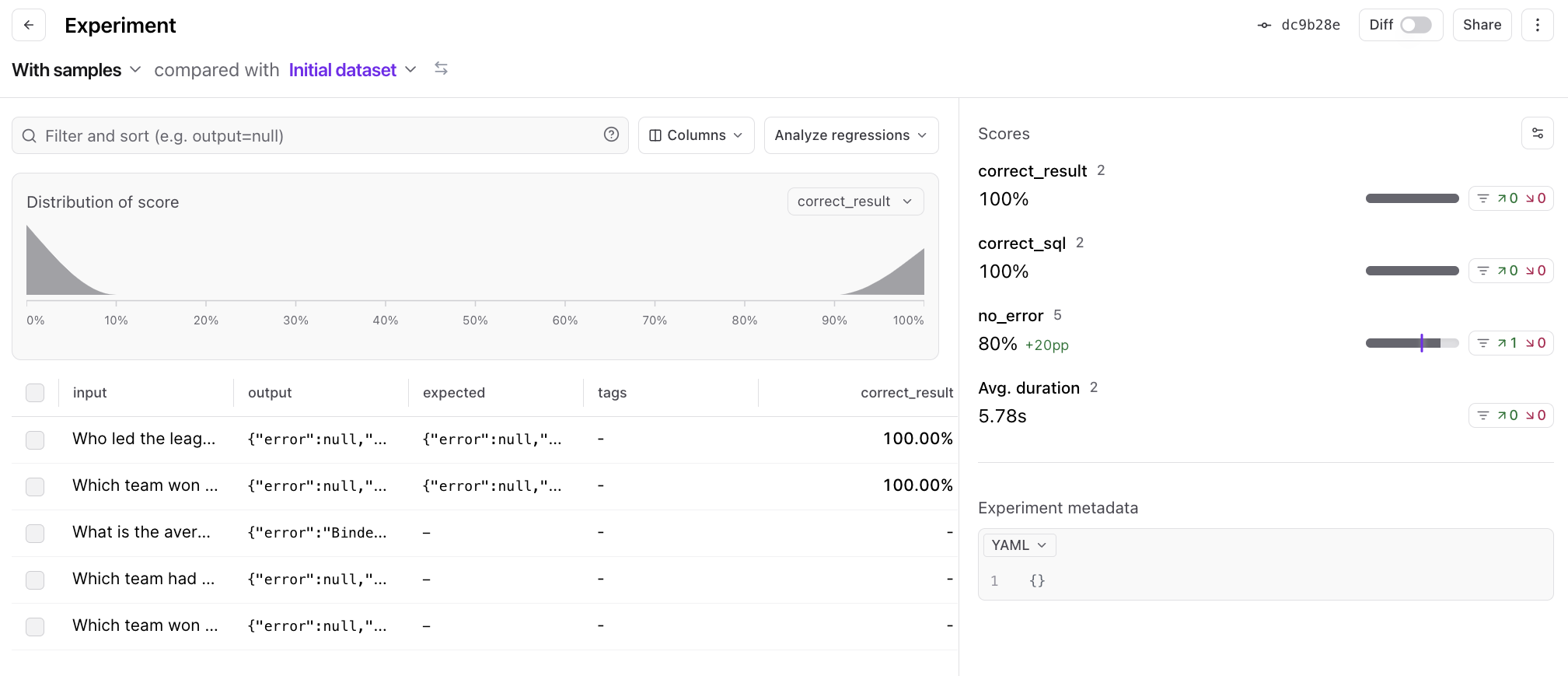
Trying GPT-4
Just for fun, let’s wrap things up by trying out GPT-4. All we need to do is switch the model name, and run ourEval() function again.